大規模言語モデル(LLM)に基づくアプリケーションを構築する際、ドキュメント解析は多くの場合、最初のハードルとなり、最終的な成果を左右する重要な要素となります。RAG(検索拡張生成)システムであれ、自動化されたワークフローであれ、高品質なテキスト抽出は不可欠です。
今回は、強力なドキュメント解析ツールである MinerU を紹介し、Dify 内で統合して使用する方法をステップバイステップで解説します。
MinerU とは?
MinerU は、OpenDataLab によって立ち上げられた、インテリジェントでオープンソースのドキュメントデータ抽出ツールです。画像、数式、表などの混合コンテンツを含む PDF ファイルや Web ページを、Markdown などの機械に適した形式に正確に変換することに特化しており、複雑なドキュメント解析の課題を解決します。
その主な利点は以下の通りです:
- 高精度な解析:テキストを抽出するだけでなく、ドキュメントの構造情報も保持します。
- 多形式サポート:PDF、電子書籍、画像の処理において優れた能力を発揮します。
- オープンソース・フレンドリー:オープンソースモデルを提供し、セルフホスト型のデプロイメントをサポートすることで、データセキュリティを確保します。
Dify での MinerU プラグインの使用
Dify のプラグインエコシステムは現在非常に充実しており、公式の MinerU プラグインも利用可能です。開発者はワークフロー内でその強力な解析機能を簡単に活用できます。
1. プラグインマーケットからのインストール
まず、Dify のプラグインマーケットで「MinerU」を検索すると、このプラグインが見つかります。
2. ツールの統合
インストールが完了すると、Dify のツール(Tools)タブで確認できます。
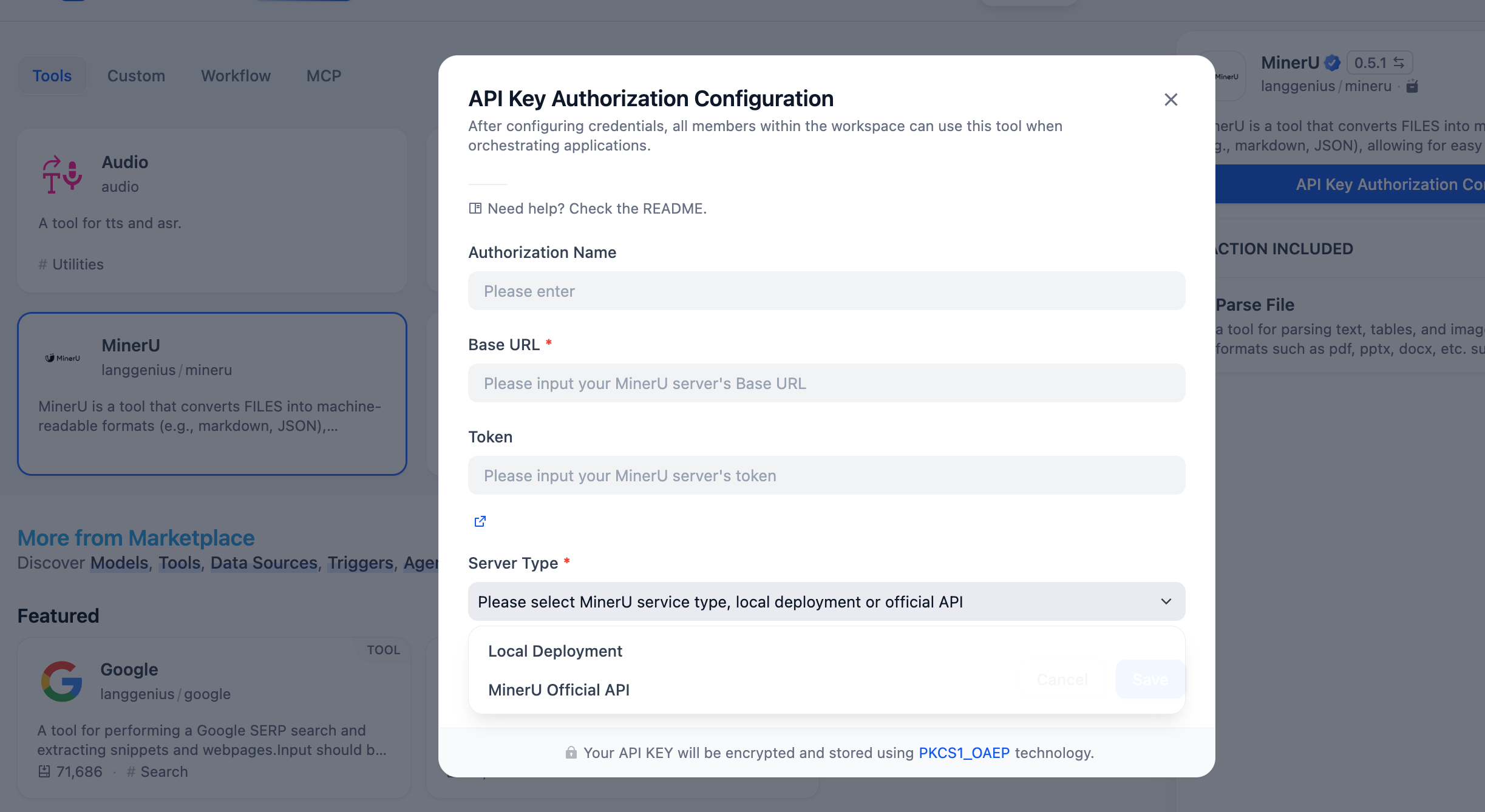
3. プラグインの設定
MinerU プラグインを使用する前に、簡単な設定が必要です。
設定ガイド:2つの統合方法
Dify で MinerU を実行するには、主に2つの設定方法があり、SaaS ユーザーおよびデータを完全に管理したいエンタープライズユーザーに適しています。
方法1:公式 API Key を使用する(迅速な体験に推奨)
これは最もシンプルで手早い方法であり、ほとんどのユーザーに適しています。
- MinerU 公式サイトの Token 管理ページにアクセスします:https://mineru.net/apiManage/token
- 登録/ログイン後、新しい API Key を作成します。
- Dify の MinerU プラグイン設定ページに戻り、申請した Key を入力します。
方法2:セルフホスト・デプロイメント(オープンソースソリューション)
データのプライバシー要件がある企業ユーザーや、大規模な処理が必要な場合は、Docker またはソースコードを使用して MinerU サービスを自分でデプロイすることを選択できます。
- プロジェクト URL:https://github.com/opendatalab/MinerU
GitHub リポジトリのデプロイメントドキュメントを参照して、サービスを開始できます。デプロイ後、Dify プラグイン設定で自構築サービスの Base URL を入力すれば、呼び出すことができます。
ローカルデプロイメントガイド
MinerU の強力な機能をローカルで体験したい場合は、以下の手順に従ってください。
注意:MinerU には特定のハードウェアおよびソフトウェア要件があります。Linux / Windows / macOS システムで Python 3.10-3.13 を推奨します。GPU アクセラレーションには Volta アーキテクチャ以降の GPU、または Apple Silicon が必要で、最低 6GB の VRAM が必要です。
方法1:pip または uv を使用してインストール
pip install --upgrade pip
pip install uv
uv pip install -U "mineru[all]"方法2:ソースコードからインストール
git clone https://github.com/opendatalab/MinerU.git
cd MinerU
uv pip install -e .[all]ヒント:
mineru[all]にはすべてのコア機能が含まれており、Windows / Linux / macOS システムと互換性があり、ほとんどのユーザーに適しています。VLM モデル用の推論フレームワークを指定する必要がある場合、またはエッジデバイスに軽量クライアントのみをインストールする場合は、拡張モジュールインストールガイドを参照してください。
方法3:Docker を使用してデプロイ
MinerU は便利な Docker デプロイメント方法を提供しており、環境を素早くセットアップし、厄介な互換性の問題を解決するのに役立ちます。詳細は Docker デプロイメント手順を参照してください。
基本的な使用方法
インストール完了後、デバイスが GPU アクセラレーション要件を満たしている場合、簡単なコマンドラインでドキュメント解析を行えます:
mineru -p <input_path> -o <output_path>GPU をサポートしていない場合、バックエンドとして pipeline を指定することで、純粋な CPU 環境で実行できます:
mineru -p <input_path> -o <output_path> -b pipelineより高度な使用方法、WebUI オプション、詳細な設定については、MinerU 公式 GitHub リポジトリを参照してください。
実践的なユースケース:複雑なフォームの解析
MinerU を統合した後、Dify ワークフローで何ができるでしょうか? 非常に典型的なシナリオは、複雑なフォームの構造化抽出です。
発注書、医療領収書、財務諸表などのスキャンコピーや PDF が山積みになっていると想像してください。これらを直接 LLM に投げても、フォーマットが乱れているために認識エラーが発生することがよくあります。
Dify ワークフロー(Workflow)では、次のように編成できます:
- ファイルアップロード:ユーザーは処理が必要な PDF ファイルをアップロードします。
- MinerU 解析:MinerU ツールを呼び出して、PDF を明確な Markdown 構造を持つテキストに変換します。このステップにより、表や階層関係が見事に復元されます。
- LLM 抽出:解析された Markdown コンテンツを LLM に渡し、スキーマに基づいて主要なフィールド(注文番号、金額、日付など)を抽出させます。
「Dify + MinerU」の組み合わせにより、これまで頭痛の種だった非構造化ドキュメントの処理が、瞬時にスムーズで効率的なものになります。ぜひ Dify プラグインマーケットで体験してみてください!